Making LLVM GEP safer in Haskell
In today's article, I will showcase how Haskell's typesystem can be used to simplify code generation and reduce the chance of bugs involving the LLVM getelementptr instruction.
Intro to the GEP instruction
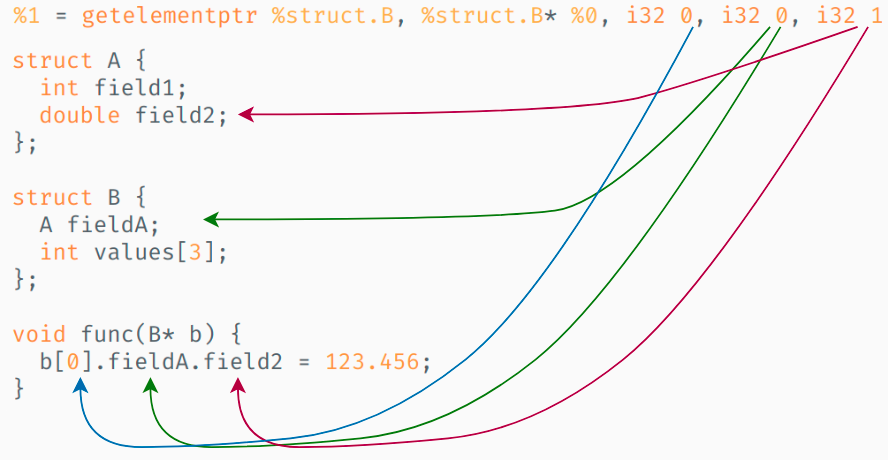
LLVM as a compiler framework offers many different low-level instructions, one of which being the getelementptr instruction (commonly abbreviated as just "gep"). With gep, you can compute derived pointers/addresses of a nested type inside another data structure, starting from a pointer. It does this by making use of type information and a list of indices into the struct that are supplied.
Here's a small snippet of C++ code and the corresponding instructions that the compiler generates (some details omitted for clarity):
struct A {
int field1;
double field2;
};
struct B {
A fieldA;
int values[3];
};
void func(B* b) {
b->fieldA.field2 = 123.456;
}; First some type definitions:
%struct.B = type { %struct.A, [3 x i32] }
%struct.A = type { i32, double }
; Instructions for function "func":
define dso_local void @_Z4funcP1B(%struct.B* %0) {
; Address to field2 is calculated:
%1 = getelementptr %struct.B, %struct.B* %0, i32 0, i32 0, i32 1
; And 123.456 is written to it:
store double 1.234560e+02, double* %1, align 8
ret void
}If we take a closer look at the line with the gep instruction, we see that a list of indices is used to index into the B datastructure. The indices correspond with the following:
- 0: offset from the initial pointer to object of type B
- 0: first field inside the B struct (= struct A)
- 1: second field inside the A struct (= double)
If we want to generate similar code using the llvm-hs library in Haskell, we need to write the following code:
codegen :: ModuleBuilder ()
codegen = do
let doubleType = FloatingPointType DoubleFP
aType <- typedef "A" (Just $ StructureType False [i32, doubleType])
bType <- typedef "B" (Just $ StructureType False [aType, ArrayType 3 i32])
function "func" [(ptr bType, "b")] void $ \[b] -> do
pointer <- gep b [int32 0, int32 0, int32 1]
store pointer 0 (double 123.456)
retVoid
return ()
main :: IO ()
main = do
let moduleIR = buildModule "example" codegen
output = ppllvm moduleIR
T.putStrLn outputThe translation is straight-forward, but the gep instruction has some problems:
- Types are indexed by integers: hard to remember which value corresponds to which type
- Manual entry of indices: error-prone
- Indices need to be repeated each time you use a gep: tedious
- It is possible to provide an empty list of indices which doesn't make sense (it's basically a no-op)
The good thing is that we have some options to fix these issues. Because we are using the Haskell bindings for LLVM, we can use Haskell as a "meta-programming" language for LLVM. Let's see what we can do.
The Indices datatype
First of, we can start by making a dedicated Indices datatype, that handles the complexity of the gep instruction. For this to be possible, we need to take a few rules into account regarding the GEP instruction:
- A gep with just index 0 is a no-op (will return address of current pointer).
- Two gep instructions can be combined if the result address of the first gep is used in the second instruction.
- If geps are combined: if the first index of second gep is 0, it can be skipped (because of the first rule).
Written in pseudo-code, this looks as follows:
- [0] = no-op
- [0, 1] + [0, 2, 3] = [0, 1, 2, 3]
- [0, 1] + [1, 2, 3] = [0, 1, 1, 2, 3]
Given these rules, we can create the following datatype that takes all this into account:
newtype Indices = Indices (NonEmpty Operand)
instance Semigroup Indices where
Indices lhs <> Indices rhs =
let rhs' = if NonEmpty.head rhs == int32 0
then NonEmpty.tail rhs
else NonEmpty.toList rhs
in Indices $ NonEmpty.head lhs :| (NonEmpty.tail lhs ++ rhs')This newtype and Semigroup instance gets us quite far and allows us to compose indices together. However, there's nothing stopping us from composing indices together in the wrong order or in other incorrect ways, which can lead to an invalid list of indices. This can in turn potentially lead to weird bugs (that can only be observed at runtime) because of wrongly calculated pointer offsets.
Keeping track of indices at the type level
Luckily, we can make use of Haskell's typesystem to prevent exactly these sources of bugs! If we think of the indices as a path used to index a data structure, we can make it so paths can only be composed if the end of the first path lines up with the start of the second path. We can keep track of this fact by using two phantom type variables representing the start and end of a path. This gives us the following data type:
newtype Path (start :: k) (end :: k) = Path (NonEmpty Operand)
-- Next line prevents usage of `coerce` to bypass type-safety:
type role Path nominal nominalThe phantom type variables give us additional type safety, but they have changed the kind of Path (to k -> k -> Type). This makes it incompatible with the Semigroup typeclass. This isn't too bad though, since we can think of a new function/operator to compose paths together.
(->>) :: Path a b -> Path b c -> Path a c
Path a2b ->> Path b2c =
let b2c' = if NonEmpty.head b2c == int32 0
then NonEmpty.tail b2c
else NonEmpty.toList b2c
in Path $ NonEmpty.head a2b :| (NonEmpty.tail a2b ++ b2c')Note: I tried writing a Category instance for Path, but it turns out that there's no good implementation for id that works in all situations. It does form a Semigroupoid (from the semigroupoids package), but I didn't want to pull in an extra dependency for just one type class/function.
Now that we have this Path datatype, we can create a type-safe drop-in replacement for the gep instruction:
addr :: Path a b -> Operand -> IRBuilderT ModuleBuilder Operand
addr path pointer = gep pointer (pathToIndices path)
where
pathToIndices :: Path a b -> [Operand]
pathToIndices (Path a2b) = NonEmpty.toList a2bBecause gep is often used in combination with load and store instructions, we can write additional helper functions to simplify these too:
-- This works very similar to C: index into a structure, and then get (load)
-- the value at that address.
deref :: Path a b -> Operand -> IRBuilderT ModuleBuilder Operand
deref path pointer = do
address <- addr path pointer
load address 0
-- Same comment applies here, but with storing a value at a specific address.
assign :: Path a b -> Operand -> Operand -> IRBuilderT ModuleBuilder ()
assign path pointer value = do
dstAddr <- addr path pointer
store dstAddr 0 valueYou can now even create a helper function to copy over specific parts of a datatype (a function I ended up using quite a bit when porting over C code!):
-- This copies a (sub-)datatype of src into dst (at the same index offset).
copyPath :: Path a b -> Operand -> Operand -> IRCodegen r ()
copyPath path src dst = do
value <- deref path src
assign path dst valueNow that we're armed with all these helper functions, the only thing that is left is to create paths to index into our data structure and compose them together. Note that this is the only place now where you need to be careful constructing the path. Afterwards, the typesystem makes sure all derived paths are correct by construction.
We can now port the earlier mentioned C++ program to LLVM as follows:
-- A helper datatype, so we can keep track of start and end of a Path
-- at the type level
data Datatype
= A
| B
| Field1
| Field2
| Value
| ArrayOf Datatype
-- Note: Not all of these Paths are needed, but are added as examples
a :: Path 'B 'A
a = Path (NonEmpty.fromList [int32 0, int32 0])
values :: Path 'B ('ArrayOf 'Value)
values = Path (NonEmpty.fromList [int32 0, int32 1])
valueAt :: Integer -> Path 'B 'Value
valueAt i = Path (NonEmpty.fromList [int32 0, int32 1, int32 i])
field1 :: Path 'A 'Field1
field1 = Path (NonEmpty.fromList [int32 0, int32 0])
field2 :: Path 'A 'Field2
field2 = Path (NonEmpty.fromList [int32 0, int32 1])
codegen = do
let doubleType = FloatingPointType DoubleFP
aType <- typedef "A" (Just $ StructureType False [i32, doubleType])
bType <- typedef "B" (Just $ StructureType False [aType, ArrayType 3 i32])
function "func" [(ptr bType, "b")] void $ \[b] -> do
assign (a ->> field2) b (Constant.double 123.456)
retVoid
return ()
main :: IO ()
main = _ -- same as beforeAnd we can verify it still generates the correct LLVM code:
; ModuleID = 'example'
%A = type {i32, double}
%B = type {%A, [3 x i32]}
define external ccc void @func(%B* %b_0) {
%1 = getelementptr %B, %B* %b_0, i32 0, i32 0, i32 1
store double 1.234560e2, double* %1
ret void
}Conclusion
In this post I showed how we can make the LLVM gep instruction safer and easier to use in Haskell by making good use of the typesystem. If you want to see this idea being used in action, you can take a look at this commit where I managed to remove all raw gep instructions by making use of the Path abstraction. The code is slightly different compared to what is presented in this blogpost, but the idea is the same.
If you are interested in more content like this, follow me on Twitter. Feel free to contact me if you have any questions or comments about this topic.