Static analysis using Haskell and Datalog
In today's post, I will give a step-by-step tutorial how you can write sophisticated analyses in Soufflé Datalog controlled by Haskell using the souffle-haskell library. In this article I will assume you've already read the README or watched this talk where I explain the basics of the library.
In this guide, I will use a name-shadowing analysis for a simple language as an example. The analysis is not that complicated, but it does allow me to showcase some of the more interesting aspects when mixing Datalog and Haskell.
Anatomy of an analysis
If we look at an analysis from a bird's-eye view, it consists of a few steps:
- Determine what you want to analyze;
- Decompose your analysis in terms of simple facts;
- Traverse over your data, deducing simple facts along the way;
- Compute derived facts in Datalog and process your data using the new-found results back in Haskell.
In each of the following sections, we will go over each of these steps in more detail.
Find something to analyze
Before we can start writing an analysis, we will first need something that we can analyze! Here's a simple (though somewhat contrived) expression-based language that has support for scoped blocks of code and variable assignment:
With this language, we can now create a small program:
This corresponds with the following pseudo-code:
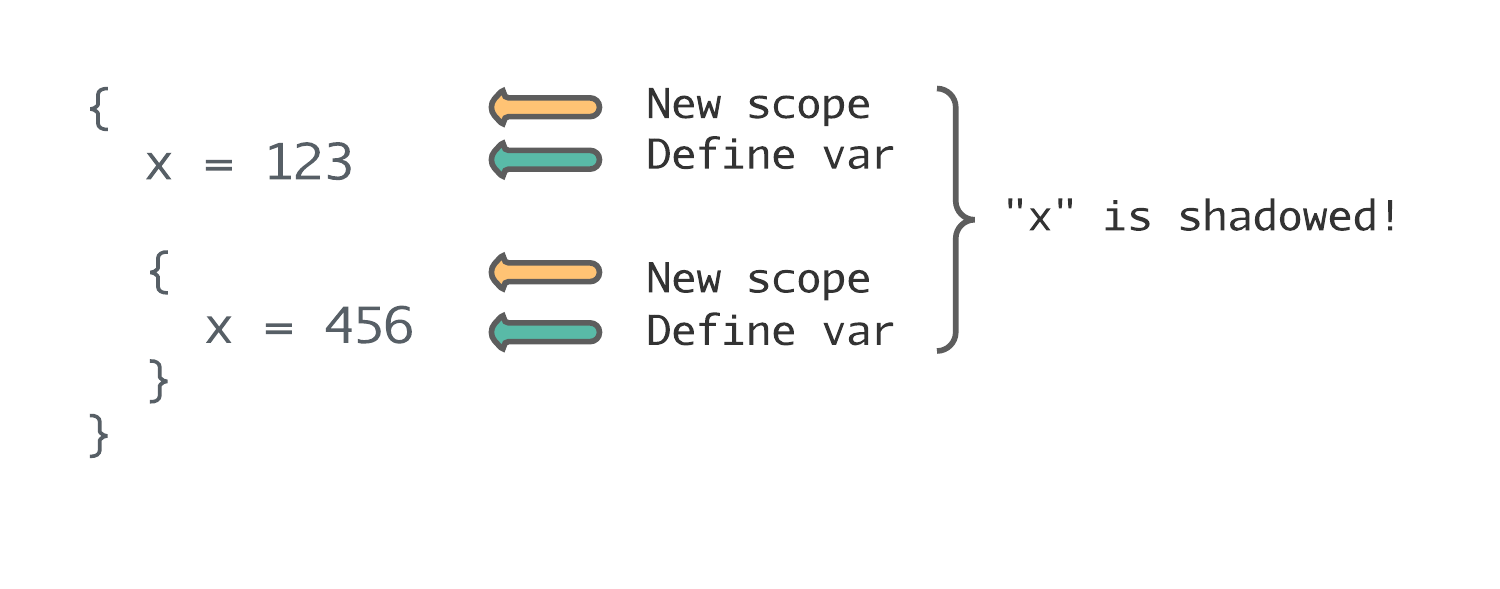
{ // First scope starts here
x = 123 // <─┐
{ // Second scope starts here │
x = 456 // Should give warning, shadows first assignment ─┘
}
}With this language, you can also have another situation where a variable shadows a previously declared variable in the same scope:
{
x = 1 // <─┐
x = 2 // Shadows variable on previous line ─┘
}I won't be going over the second case in detail (to keep the article from becoming too long), but you can solve it in a comparable way as the first example.
Decompose analysis in terms of facts
So how did I determine in the previous examples that a variable was shadowed? I made certain observations (facts) about the code and then combined these facts to form conclusions about the data. This is very close to how a logic programming language like Datalog works!
For name shadowing, what are the basic facts? First of all, we need to keep track of which variables are defined in the program. Secondly, another important fact that we can use is which scopes are nested inside each other.
In Datalog, we can write a query that uses these facts to check for name shadowing:
// Declarations for the facts and relations used in our analysis:
.decl define(scope: symbol, variable: symbol)
.decl nested_scope(scope: symbol, sub_scope: symbol)
.decl shadowed(variable: symbol)
// All data coming from Haskell needs to be marked as inputs,
// the results of the analysis are marked as outputs.
.input define
.input nested_scope
.output shadowed
// Read this query as follows:
//
// A variable is shadowed iff:
// it is defined in a scope 'scope'
// AND it is defined again in scope 'sub_scope'
// AND 'sub_scope' is a scope nested inside of 'scope'.
shadowed(variable) :-
define(scope, variable),
define(sub_scope, variable),
nested_scope(scope, sub_scope).That's all there is to it! As you can tell, the transformation from the logical description of the analysis to the actual Datalog code is quite straight-forward.
When creating your Datalog queries, you can either check for "positive" or "negative" scenarios. With positive scenarios, I mean Datalog queries that search which values match certain criteria. Negative scenarios on the other hand check if an error situation occurred (like in this example).
One final thing to note here is that in a more complete implementation the query would contain extra information (for example line numbers). This has some additional benefits:
- You can use the line numbers in your query results (e.g. compiler error messages).
- You can check more things if you have more information (such as name shadowing in same scope).
Deducing facts of your data
Now that we have written our Datalog analysis (and saved it as name_shadowing.dl), we can start calling it from Haskell. For this we will need some code to bind to the corresponding Datalog code:
-- A type for representing our Datalog program:
data NameShadowing = NameShadowing
-- Types that correspond with our Datalog facts:
type Scope = Int32
data Define = Define Scope Var
deriving Generic
data NestedScope
= NestedScope
{ _scope :: Scope
, _subscope :: Scope
} deriving Generic
data Shadowed = Shadowed Var
deriving (Generic, Show)
-- Some instances for communicating between Haskell and Datalog:
instance S.Program NameShadowing where
type ProgramFacts NameShadowing = '[Shadowed, Define, NestedScope]
programName = const "name_shadowing"
instance S.Fact Define where
type FactDirection Define = 'S.Input
factName = const "define"
instance S.Fact NestedScope where
type FactDirection NestedScope = 'S.Input
factName = const "nested_scope"
instance S.Fact Shadowed where
type FactDirection Shadowed = 'S.Output
factName = const "shadowed"
instance S.Marshal Define
instance S.Marshal NestedScope
instance S.Marshal ShadowedThis approach should look familiar if you've read the souffle-haskell README. Once we've written the binding code, we can write a function that traverses our data and deduces facts:
deduceFacts :: S.Handle NameShadowing -> Expr -> S.SouffleM ()
deduceFacts handle expr = runReaderT (go expr) rootScope
where
-- Our function needs to keep track of which scope it is in.
-- Scope at root level is 0, every nested scope increases by 1.
-- We can use the Reader monad for keeping track of scope since
-- we only ever modify it locally and for the rest only
-- perform reads.
rootScope = 0
newScope s = s + 1
go expr = case expr of
-- Assignments are simple: we lookup the current scope
-- and store the fact that a variable is defined at this scope.
Assign var _value -> do
currentScope <- ask
S.addFact handle $ Define currentScope var
-- Blocks are more complicated since the scope changes when you
-- enter a block. We can use Reader here for easy access to the
-- scope info. If we are in a nested scope, then we can submit
-- this fact to Datalog as well.
Block exprs -> local newScope $ do
currentScope <- ask
when (currentScope > rootScope) $ do
let prevScope = currentScope - 1
S.addFact handle $ NestedScope prevScope currentScope
-- Don't forget to handle the nested sub-expressions:
traverse_ go exprsPhew! That was a dense piece of code. Hopefully the comments in between helped reason about the code. As you can see, computing facts based on a single point of data is easy. If a fact is based on some context and it requires information about multiple places in the data, it gets a little more tricky. Here I used manual recursion and monads to solve this issue, but you are completely free to compute facts in any possible way based on the input data. (I haven't tried this out myself yet, but I have a feeling this might be a great fit for comonads..)
Processing the analysis results
We are almost there! The final step is to run the analysis and use the computed results in the rest of your library or application code.
main :: IO ()
main = S.runSouffle NameShadowing $ \case
Nothing ->
liftIO $ putStrLn "Failed to load program."
Just prog -> do
deduceFacts prog exampleExpr
S.run prog
shadowedVars :: [Shadowed] <- S.getFacts prog
-- Here we only print out the results, but you could
-- use the results for error reporting, optimizations, ...
liftIO $ do
putStrLn "Shadowed variables in expression:"
traverse_ print shadowedVarsBy the way, if you have multiple fact types you need to retrieve from Soufflé, you can make clever use of Haskell's typesystem to collect all these different facts with very little code:
data Fact1 = ...
data Fact2 = ...
data Fact3 = ...
data AnalysisResult = AnalysisResult [Fact1] [Fact2] [Fact3]
main = runSouffle MyAnalysis $ \case
Just prog ->
-- For each of the following calls, `getFacts` will retrieve a different
-- type of fact (all based on type information):
result <- AnalysisResult <$> S.getFacts prog
<*> S.getFacts prog
<*> S.getFacts prog
-- etc...Conclusion
In today's post, I showed how you can use Datalog from your Haskell code to perform complex analyses. By first destructuring an analysis in terms of simple facts and then writing queries based on those facts, we can write our analyses in a way close to how we reason about our code.
In this article we focused on an analysis for a simple language, but this approach is not limited to this usecase. For example, you can also use it for when you need to process complex data in a webserver, in data science, ...
If you want to see a more complicated example of this approach, here's a dead code elimination analysis. This example is more complicated than the one explained in this post and uses techniques like control flow analysis (in Datalog) to compute all dead code paths in a program. And if you really want to go all-in, you could structure your different analyses to gather all facts in a single traversal by combining them into one fold.
If you have any questions or thoughts about this article, let me know on Twitter. If you want to play around with the code from this post, it can be found here.